Your own private ChatGPT in a box that fits in your pocket
What if you could run a fully local AI assistant on 25 watts? I built Monroe: a plug-and-play box with RAG, streaming chat, and no cloud dependency. Here's the architecture, the compromises, and what I learned about building AI systems under real hardware constraints.
Late 2024, a friend and I were experimenting with AR glasses. Ou goal was to keep the glasses thin, push heavy compute elsewhere. That elsewhere became a Jetson Orin Nano Super 8GB, a compact GPU-capable unit that fit in a pocket and only consumed 25W at max performance. We eventually split for vision reasons, but I kept experimenting with the device. One question stuck with me: if this tiny box can handle 3D graphics at an impressive speed, why not run quantized LLMs, and does it have the potential to be a consumer friendly local and private ChatGPT ?
That gave birth to the Monroe project. A project closely supervised by M. Valéry Farcy and M. Aurélien Burget, two very talented people part of the Espoir Entrepreneur program.

The Jetson Orin Nano constraints are both generous and brutal. Enough GPU for real work, but small enough that every background process matters. I started tracking hardware limits explicitly: 8GB VRAM, NVMe storage, CUDA/Tensor cores. Treating memory as a scarce ressource. Suddenly you care about resident processes, allocation spikes, caching behavior, and how your UI can reduce backend work. Monroe was both a systems project and an AI project.
I converged on a modular architecture. An LLM server on the Jetson exposing an OpenAI-compatible interface. A RAG server for document ingestion and retrieval. A client UI that handles streaming, history, citations, and routing. This diagram shows the modular architecture but each box hides a series of compromises.
Making local inference feel like ChatGPT meant standardizing on the OpenAI chat API contract. I wanted to avoid the "one custom client for one box" trap. With a standard interface, any web client, CLI, or future experiment can connect without rewriting the interface each time. Even apps that were originally designed to work with the OpenAI API. For initial prototyping i settled on serving models through Ollama on port 9000, with quantization assumptions like Q4_K_M in llama.cpp style (Thank you Unsloth).
A rough mental model for parameter memory is:
An 8B model at 4-bit weights consumes roughly bytes = 4GB, before KV cache, activations, fragmentation, and runtime overhead. So I basically went for Q4 quantization for every OSS model I could.
A local assistant becomes lovable when it feels alive: token streaming, fast first response, stable UX. In the UI client code, chat requests are built in OpenAI format and streamed from /v1/chat/completions. I also implemented a cheap token estimator:
implemented as ceil(text.length/4) to avoid expensive tokenization just to keep context under budget.
At some point, i realized local inference alone was limited in terms of usefulness. Models hallucinate, forget, lack your context. I set a harder target: fit a practical RAG pipeline under strict memory and keep it fast enough to feel seamless.
I implemented a DocumentProcessor handles PDFs page by page and DOCX/TXT directly into text segments with metadata. PDF page segmentation is convenient and enables source grounding later with page numbers and filenames.
Chunking was the next step. Small chunks improve precision, large chunks preserve context, overlap reduces boundary loss, but all of it impacts index size, embedding time, and prompt budget. My chunker uses a target size around 1000 tokens, with overlap (of a 100 tokens), using the same naive token estimate heuristic (len/4). It generates chunks with metadata including token counts and chunk IDs.
Now we had to choose an embedding model that fit Jetson constraints, was multilingual (at least English + French for demo purposes), and be deployable. I settled on paraphrase-multilingual-MiniLM-L12-v2 (117M params, 384-dim embeddings, multilingual) as a balanced point. In code, the embedder loads SentenceTransformer and performs batched encoding. With quite a focus on optimization : batch size vs memory spikes, GPU vs CPU fallback, and the decision to keep the model loaded. In the RAG API, I moved toward keeping the embedder loaded globally, not unloading each time, removing forced GPU cache clears. This killed latency jitter.
For vector search, ChromaDB runs in persistent mode with an HNSW index configured for cosine similarity. The retrieval query returns documents, metadata, and distances. The query engine filters by similarity threshold and top-K selection, then formats results with useful metadata. I also looked into keeping vector storage compact.
The RAG API is a FastAPI server managing sessions, uploads, and queries. Sessions get UUIDs and live in a session manager. Document uploads trigger processing and indexing. Queries return structured results. This makes retrieval a service, not a notebook hack.
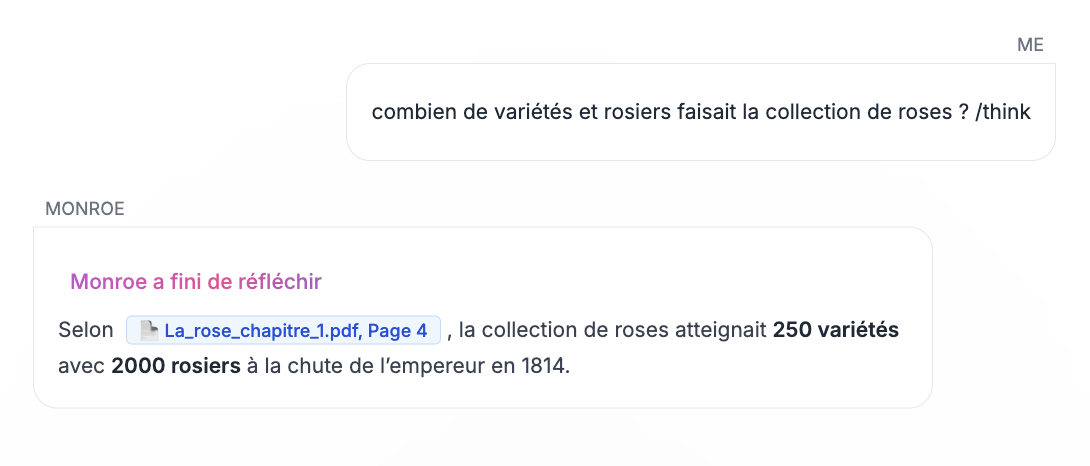
A RAG system isn't useful if it can't show where answers come from. In the chat UI, RAG context is injected into the system prompt as [DATA N], with explicit instructions to cite those snippets when used. The RAG integration plan treats citations as a UI feature. Citations would be highlighted as you can see in the screenshot.
One of the trickiest UX problems with local models is inconsistency. Sometimes they answer instantly and well. Sometimes they need reasoning depth. Sometimes they waste time "thinking" on trivial prompts. I implemented a prototype for algorithmic prompt complexity detection to tag prompts for Qwen3 models: complex prompts get /think, simple ones get /no_think, these slash commands were Qwen exclusive but good enough for experimentation. A router module scores prompts on linguistic complexity, syntactic complexity, semantic density, chain-of-thought markers, and more. The router is a lightweight service targeting low memory and fast analysis. It made the experience much more enjoyable, as models weren't thinking by default (which for Qwen models can take several minutes).
For LAN access, any client device could tap into port 9000 of the the Monroe box (assuming it was connected to the local router through WiFi or Ethernet). Simple but effective.
You could also go for a USB plug-and-play setup. The Jetson USB-C gadget exposes a local interface with DNS/DHCP, resolving as monroe.local over the USB link. The test sequence is: plug the host, ping monroe.local, then curl http://monroe.local:9000/v1/models. This was great for UX.

I had Laval Mayenne Technopole and ESIEA students test Monroe. Feedback was consistent: it felt compact, smooth, and private.
Then came Pépite Day, a regional event where selected entrepreneurs could showcase their projects. Conversations, technical and non-technical, confirmed something important, people LOVE a good UX over any model performance talk.
My teammate Alexis Garreau provided a ton help, especially on cybersecurity and controlled-network management. He made the box a lot more secure, as i'm definitely not a cybersecurity guy.
One element i would like to share and emphasise on this story is the amount of work i was putting into this project. In mid-2025, I was handling demanding coursework, a professional IT logistics project management role where i was actively developing an optimization software for a physical platform, and Monroe development plus weekly interviews. By July, I was clearly exhausted. In August, I took some time off. In September, i decided to try doing some informal interviews with experts and managers from different companies to test the waters for this new product, emphasis on informal becausei had done formal interviews all year and it sounded promising for "confidential local AI." Informal interviews, where you hear what people actually do, revealed something different: these people saw foreign cloud services as "safe enough," Office 365 + Copilot was already there, AI clusters were already in Azure/Vertex/managed infra, and hardware ownership, even compact, was seen as friction.
And after a dozen informal interviews, I decided to pause Monroe. Not emotionally. Not dramatically. Just rationally. Entrepreneurship isn't building what's cool. It's building what survives adoption.
Even if Monroe isn't my active project anymore, it's one of the most formative engineering experiences I've had. It forced me to build a full stack system where constraints are real.
Local inference is not the product. The product is everything around it: APIs, routing, UX, caching, failure modes. RAG pipelines with It's ingestion + chunking + indexing + retrieval + filtering + citations + evaluation. And a beautiful responsive interface with an easy setup.
Monroe began as an obsession with making a small GPU box useful. It ended as a year-long exercise in building a full AI system where every choice has a cost: memory, latency, usability, adoption.
I will keep the prototype. I still love the idea. But in 2026, my focus shifts toward deeper research questions, and toward the kind of work that belongs in a lab.
Bonus: Here's our Pépite Day booth :)
